LRU cache - map vs unordered_map
Date: 04 Dec 2012Author: Erik Dubbelboer
Recently I needed a simple LRU cache. Since the standard library doesn’t provide one I decided to write one myself.
The cache needed a simple interface to get and set items and needed to be at least logarithmic in complexity. Something like:
template <class KeyType, class ItemType>
class LRUCache {
LRUCache(size_t capacity);
size_t Capacity();
void Resize(size_t capacity);
ItemType Get(const KeyType& key);
void Set(const KeyType& key, const ItemType value);
void Remove(const KeyType& key);
};So this is what I wrote: lrucache.h
It uses an std::list to keep track of the age of items. And an std::map to store the key-value pairs.
This combination allows for all methods to be O(log n).
C++0x
I have also written a version which allows you to specify the internal container to use.
This version only works when C++0x is enabled because it requires variadic. std::unordered_map also requires C++0x.
The advantage of using std::unordered_map is that it offers O(1) (average case) access methods which allows the cache to be O(1) (average case) as well.
template <class KeyType, class ItemType, template<typename...> class MapType = std::map>
class LRUCache {
// ... (same as above)
}This version can be used in the following way:
LRUCache<std::string, int, std::unordered_map> cache(64);std::map vs std::unordered_map
When choosing which container to use for the C++0x version there are a two main points to look at. The size of your cache and the size of your keys.
std::map is implemented using a tree (red-black) while std::unordered_map uses a hash table.
In the following graph you can see that the time it takes the std::map version to access a key increases logarithmically with the size of your cache, while the std::unordered_map version is constant. For this graph I used integers as keys.
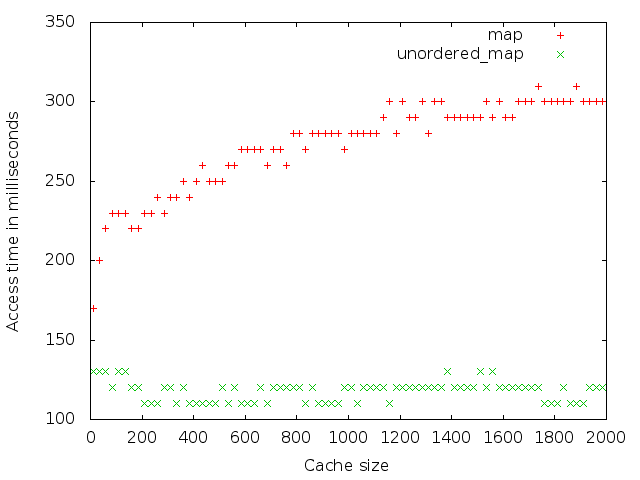
For next graph I took 1024 character long strings as keys. This shows that if you have a small cache size but big keys an std::map will probably be faster.
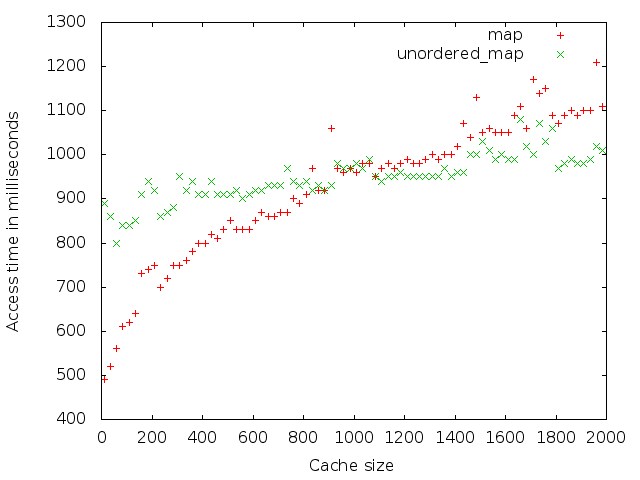
The last graph uses a fixed cache size of 1024 entries but plots the access time vs the key size. In this graph you see that at some point the time it takes the std::unordered_map to calculate the hash is much slower than the binary search std::map performs.
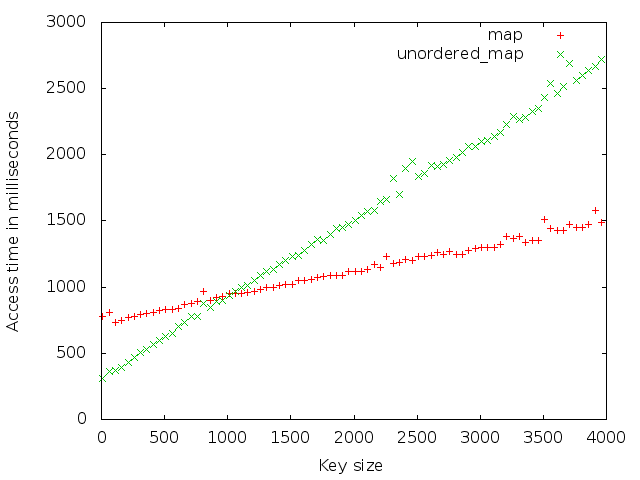
When choosing a container for your own program the best solution would be to run the benchmark yourself, with real data, and plot the result to pick the best one. The source for the benchmark can be found here, speed.cpp, together with a gnuplot script, speed.plot, to plot the result.
- All benchmarks perform 1,000,000
Get()and if the key does not existSet()operations.